
Adapting RGB Pose Estimation to New Domains
Team Size: 1
Abstract:
Many multi-modal human computer interaction (HCI) systems interact with users in real-time by estimating the user's pose. Generally, they estimate human poses using depth sensors such as the Microsoft Kinect. For multi-modal HCI interfaces to gain traction in the real world, however, it would be better for pose estimation to be based on data from RGB cameras, which are more common and less expensive than depth sensors. This has motivated research into pose estimation from RGB images.Convolutional Neural Networks (CNNs) represent the state-of-the-art in this literature, for example [1], [2], [6], [7], [8], and [9]. These systems estimate 2D human poses from RGB images. A problem with current CNN-based pose estimators is that they require large amounts of labeled data for training. If the goal is to train an RGB pose estimator for a new domain, the cost of collecting and more importantly labeling data can be prohibitive. A common solution is to train on publicly available pose data sets, but then the trained system is not tailored to the domain. We propose using RGB+D sensors to collect domain-specific data in the lab, and then training the RGB pose estimator using skeletons automatically extracted from the RGB+D data.
We present a case study of adapting the RMPE pose estimation network [2] to the domain of the DARPA Communicating with Computers (CWC) program [3] as represented by the EGGNOG data set [4]. We chose RMPE because it predicts both joint locations and Part Affinity Fields (PAFs) in real-time. Our adaptation of RMPE trained on automatically-labeled data outperforms the original RMPE on the EGGNOG data set.
Introduction:
Many multi-modal human computer interaction (HCI) systems interact with users in real-time in part by estimating the user’s pose. For example, Narayana et al.[3] describe a multi-modal interface for an avatar, in which users gesture and/or speak to direct an avatar. As shown in Figure 1, the virtual agent avatar perceives the user’s motions by estimating their pose over time. The agent analyzes the predicted joint locations (marked in yellow), and matches them to known gestures (or to no gesture) and responds appropriately. In this way, pose estimation facilitates gesture comprehension, which in turn helps the system achieve multi-modal communication via gestures and speech.
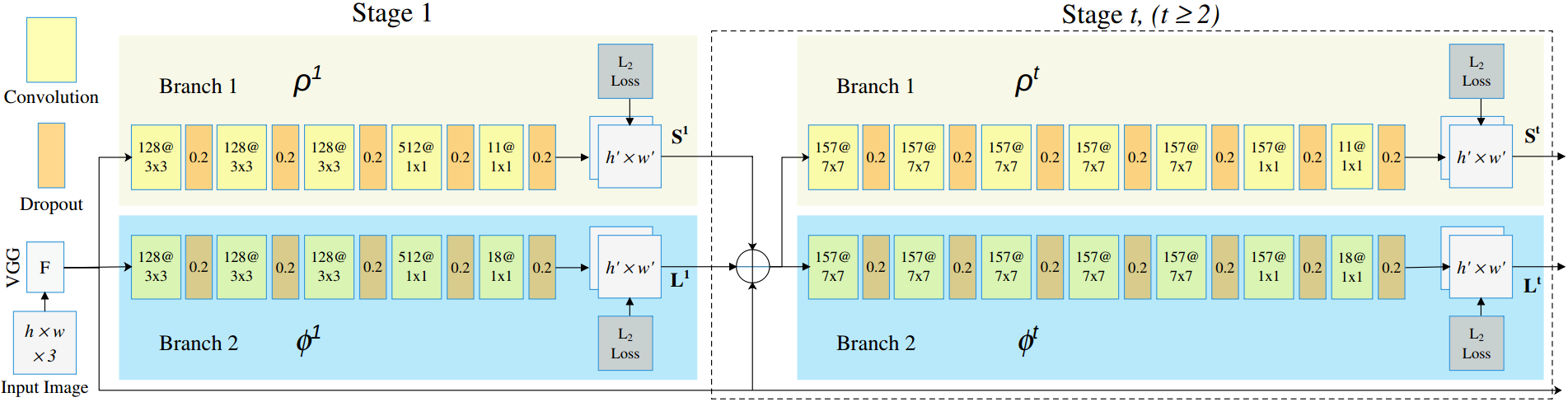
The state of the art technique for pose estimation from RGB images is the convolutional neural networks; examples include [1], [2], [6], [7], [8], and [9]. In particular we focus on RMPE [2], which is widely cited and real-time. RMPE is a multi-stage CNN that extracts the image positions of body joints (elbows, wrists, etc.) as well as part affinity fields representing the limbs that connect joints (e.g. the arm between the elbow and wrist).
One challenge in adapting RMPE (or any CNN) to a new domain is collecting the training data. Generally, pose estimator such as RMPE are trained on manually annotated data sets such as COCO [5]. Manual labeling is an expensive process, however, and prone to errors and inconsistencies in label definitions. An alternative is to collect training images with co-registered depth images (e.g. with Microsoft Kinect) and use existing pose-from-depth algorithms to automatically label the joint positions. This approach is inexpensive and quick, and makes it easy to collect large amounts of labeled training images with consistent label definitions. However, it potentially introduces errors into the training data, since the pose-from-depth algorithms make mistakes and depth data can be noisy. It is an open question how well RMPE will perform when trained on automatically-extracted skeletons.
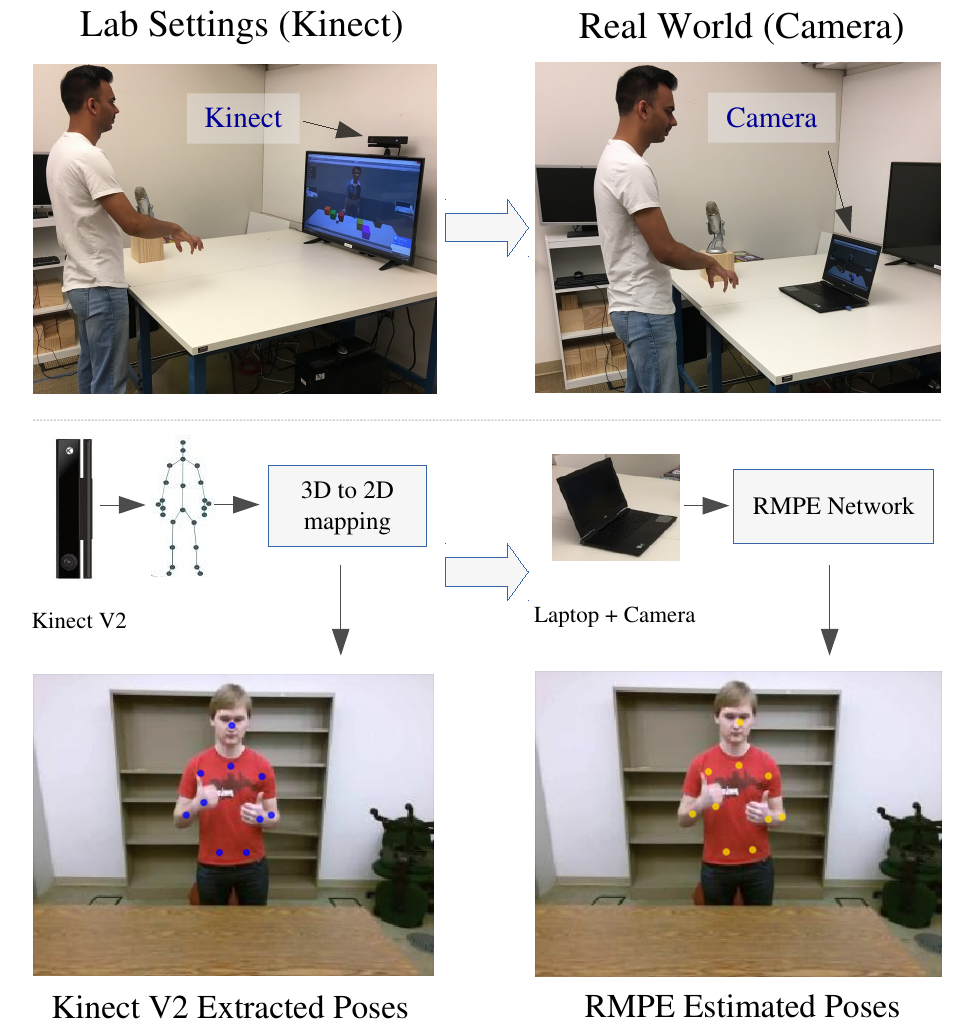
Figure 2 illustrates the adaptation scenario. The idea is to collect data with a Kinect in the lab (as shown in the upper left) and to train RMPE to label RGB images (bottom left) based on automatically-generated skeletons. Once the network is trained, it can be used outside the lab to estimate poses from traditional RGB cameras (right side of Figure 2). The final application therefore only requires a laptop and its built-in camera.
Adapted RMPE Architecture:
Experiments and Evaluation:
Detailed methodology of the experiments and their evaluation can be found here:And here is the conference paper version:
Here are some of the videos showing Kinect v2 ground truth poses in the left pane and predicted poses by our adapted RMPE system in the right pane on test dataset videos:
Conclusion:
We present a case study on adapting and retraining a popular CNN-based pose estimator (RMPE) to the EGGNOG data set. By tailoring RMPE to the HCI domain represented by the EGGNOG data set, we get better performance than if we use the pre-trained (on COCO) version of RMPE. Experiments also reveal that the EGGNOG domain only needs a two-staged RMPE to achieve strong performance, and the addition of more stages increases overhead without significantly improving performance. This paper shows too that spatial dropout regularization improves performance, even though it was not used in the original version of RMPE. Further, our analysis of retrained RMPE on EGGNOG shows that the training set should contain at least 16 human subjects and 40K training images in order to generalize.References:
- S. Wei, V. Ramakrishna, T. Kanade, and Y. Sheikh. Convolutional pose machines. CoRR, abs/1602.00134, 2016
- Z. Cao, T. Simon, S. Wei, and Y. Sheikh. Realtime multi-person 2d pose estimation using part affinity fields. CoRR, abs/1611.08050, 2016
- P. Narayana, N. Krishnaswamy, I. Wang, R. Bangar, D. Patil, G. Mulay, K. Rim, R. Beveridge, J. Ruiz, J. Pustejovsky, and B. Draper. Cooperating with avatars through gesture, language and action. Intelligent Systems Conference (IntelliSys), 2018.
- I. Wang, M. Fraj, P. Narayana, D. Patil, G. Mulay, R. Bangar, R. Beveridge, B. Draper, and J. Ruiz. EGGNOG: A continuous, multi-modal data set of naturally occurring gestures with ground truth labels. In 2017 12th IEEE International Conference on Automatic Face Gesture Recognition (FG 2017) , pages 414–421, May 2017.
- T. Lin, M. Maire, S. Belongie, L. Bourdev, R. Girshick, J. Hays, P. Perona, D. Ramanan, P. Dolĺar, and C. Zitnick. Microsoft COCO: common objects in context. CoRR, abs/1405.0312, 2014
- A. Toshev and C. Szegedy. DeepPose: Human Pose Estimation via Deep Neural Networks. CoRR, abs/1312.4659, 2013.
- A. Newell, K. Yang, and J. Deng. Stacked hourglass networks for human pose estimation. CoRR, abs/1603.06937, 2016.
- Y. Chen, Z. Wang, Y. Peng, Z. Zhang, G. Yu, and J. Sun. Cascaded pyramid network for multi-person pose estimation. CoRR, abs/1711.07319, 2017.
- B. Xiao, H. Wu, and Y. Wei. Simple baselines for human pose estimation and tracking. CoRR, abs/1804.06208, 2018.