
Attention Window and Object Detection, Tracking, Labeling, and Video Captioning
Team Size: 3
Objectives:
This project contains a series of assignments put together to build a final project with a goal of object detection, tracking, labeling, and video captioning. Here are the series of sub-tasks constituting towards the final goal:- Affine and Perspective transforms on a video: This code performs either affine or perspective transformation on an input video using OpenCV's built-in functions.
- Extract unique attention windows from each frame of a video: This code extracts attention windows from an input video.
- Detect and Track moving objects: This code implements object detection and tracking on a video.
- Object labeling: This code implements VGG based object labeling.
- Video captioning: This code demonstrated video captioning.
Extract unique attention windows:
Objective is to write a program that reads a video and produces one attention window per frame. The window represents the 'best' attention window for that frame and is written back to the disk. We implemented multiple ways to find the best attention window per frame. Some of the approaches were:
- SIFT (Scale-Invariant Feature Transform) keypoints based approach that finds the best attention window using size-response sorting
- SIFT keypoints clustering using hierarchical (HCA) and DBSCAN clustering algorithms
- Saliency based attention models (Boolean Map based Saliency)
- Here is a short report detailing about each of the approaches mentioned above.
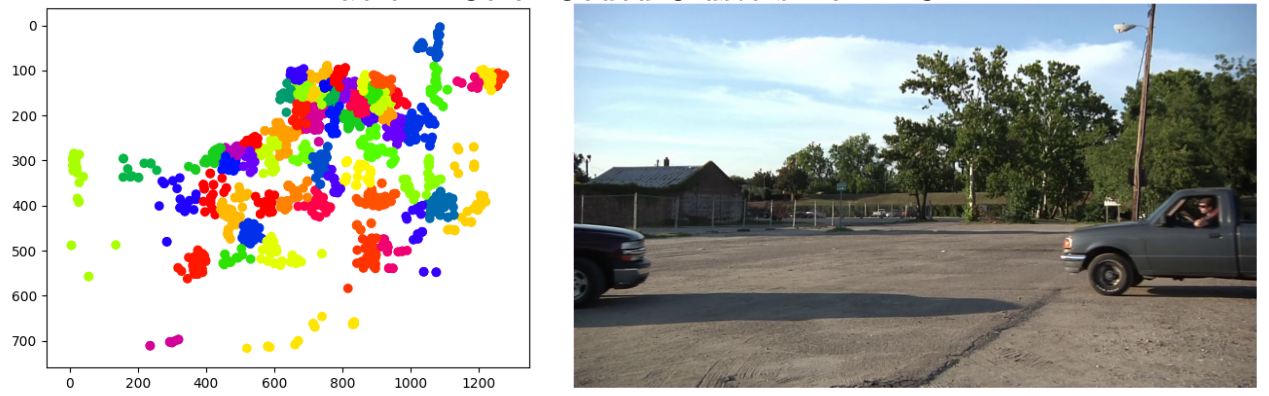

Detect and Track moving objects:
We use Mixture of Gaussians (MOG) [1] method to detect the foreground objects, along with Minimum Output Sum of Squared Error (MOSSE) filter [2] to track these objects across the entire video. For foreground and background detection we also tried the ViBe [3] algorithm but we ended up using MOG.First component of our system uses Mixture of Gaussians model which employs as the name implies, a mixture of 3-5 Gaussians to model each background pixel. The second component of our system is tracking the objects across the image sequence. MOSSE is an attractive approach since it is fast, accurate, and more importantly, doesn't require training beforehand. For our system, we chose MOSSE for these reasons. While testing these methods we found that shadows pose a major problem in detection giving many false positives.
- Here is a short report on object detection and tracking that talks about implementation details an evaluation of our system.
Here are some of the videos outputted by our system demonstrating object detection and tracking.
Object labeling:
Goal is to integrate the object detection and tracking systems by applying a pre-trained deep convolutional network (VGG [4], [5]) on the attention windows and tracked windows and classify the objects within those windows.Our system consist of three major parts. First is the attention window detection wherein the system captures the most interesting windows from a video frame. Although we applied it on a dynamic video, it is particularly useful in finding static attention windows such as house, lamp- posts, etc. Second is the tracking where the systems tracks a detected window in frame sequences though time. Both produce a list of rectangular attention windows written to a csv file. Finally, the trained VGG classier processes these attention windows to output the most probable label of that window captured either from the static background or the dynamic foreground.
VGG: It is a 16 layer Deep Convolutional Neural Network with 1000 output classes having an architecture of layers as [C-C-P-C-C-P-C-C-C-P-C-C-C-P-C-C-C-P-F-F-F], where C is Convolutional layer, P is Pooling layer, F is Fully-Connected layer.
- Here is a short report on VGG based labeling.
Video Captioning: Describing the video after object detection, tracking, and labeling.
In this section we integrate the object detection, tracking, and labeling systems with a video captioning system. We use the classification labels from VGG with their location and direction of motion to generate meaningful sentences describing the scene in the video.Our final system consist of four major modules. First is the attention window detection from the background of the video frame. Here, the system captures the most interesting (attention grabbing) windows from the background of the video frame. It detects static attention windows such as house, lamp-posts, etc. Second is the foreground detection where a foreground detecting algorithm gives us a set of objects in the foreground. On the top of this we track the foreground objects using MOSSE tracking algorithm.
For every frame, both the modules produce a set of rectangular windows that are the ’most attentive.’ Next, a trained VGG classier processes these attention windows and outputs the most probable label of that window which could be either from the static background or the dynamic foreground. This module writes a csv file with list of labels and their location, direction of motion and frame number where they were detected. Finally, we describe the video scene in sentences using the ’scene description’ module.
Video captioning: The current approach to describe the video in sentences is a simple approach based on the type of the object from the csv file. We describe the video in terms of foreground and the background that are labels as ‘moving’ and ‘still’ in the csv file. For example, following is the scene description produced for the first test video (example1.mov) and the seconds test video (example2.mp4) respectively.
- Here is a short report detailing about the individual components and their integration along with the evaluation of this system.
Here is the video-caption generated by our system for video below:
In the background, there is a barn in the middle left, a flagpole in the upper right, a boathouse in the middle left, a thresher in the middle left, a limousine in the middle left. In the foreground, a minivan (moving towards right slowly) AND a pickup (moving towards left slowly) are moving in opposite direction.
Here is another video-caption generated by our system for video below:
In the background, there is a racer in the center, a mobile home in the middle left, a maze in the center, a paddlewheel in the upper left, a aircraft carrier in the middle left, a warplane in the middle left, a liner in the upper left. In the foreground, a moving van (moving towards left slowly) , a limousine (moving towards left slowly) are moving in same direction.
The current video captioning algorithm provides a ‘text template’ which is then filled in depending on the number of objects (moving or still) in the video. Therefore, the scene description is rigid in the sense that it does not show any ‘intelligence’ in describing a scene.
Obviously, in both the examples the captions are not the best captions for respective videos. Also, the methodology used for captioning was not generalizable across various video domains. Given the time constrains, we resorted to our 'hard-coded' captioning methodology. However, in future we would like to explore the state-of-the-art, CNN-based video captioning methods published in recent years (after 2014). Ultimate goal would be to develop a generic algorithm that describes the scene in a non-rigid and intelligent manner without having a ‘text template’ to start with.
References:
- Stauffer C., Grimson W., Adaptive background mixture models for real-time tracking, The Artificial Intelligence Laboratory, Massachusetts Institute of Technology, Cambridge, MA 02139
- David S., Bolme J., Ross Beveridge, Bruce A. Draper, Yui Man Lui, MOSSE: Visual Object Tracking using Adaptive Correlation Filters https://www.cs.colostate.edu/~vision/publications/bolme_cvpr10.pdf
- O. Barnich and M. Van Droogenbroeck, ViBe: A Universal Background Subtraction Algorithm for Video Sequences https://ieeexplore.ieee.org/document/5672785
- Simonyan K. and Zisserman A., Very Deep Convolutional Networks for Large-Scale Image Recognition https://arxiv.org/pdf/1409.1556/
- Pre-trained VGG: http://www.cs.colostate.edu/~cs510/yr2017sp/more_assignments/vgg.zip