
Using RGB-based Human Skeleton Recognition for Communicating with Computers (CwC) Project
Introduction:
Brief intro to CwC:The long term goal of the CwC project is to build an AI agent that will communicate seamlessly with humans via gestures, expressions, and vocal communication just like a real human being would with another human being. The agent achieves this communication by building a shared perception with the humans using all the knowledge it acquired through all the past and current interactions with the humans. The short term goal is to get a structure of virtual blocks build from a virtual AI agent (Diana) via multi-modal communication. CSU's computer vision lab (of which I am a part of) has built this system (please see the demo video below) as a part of an active (as of 2018) DARPA project called CwC.
[[Video]]
RGB-based Skeleton Recognition for CwC:Recent work by CMU [1], [2] in human pose recognition from RGB images, produces state-of-the-art results on multiple datasets. Success of these methods can be primarily attributed to convolutional neural networks for joint detection and special techniques to associate detected joints with people in a frame. We incorporated this work to replace previous depth-based pose recognition. Task involved writing a C++ wrapper around the OpenPose library [1] and a Python server to interface this wrapper with the rest of the client’s system, along with some modifications to previous clients
As a part of my Research Seminar Course (CSU CS793), I worked on the front-end of the CwC project to replace the Kinect-based data collection module at the front-end of the Communicating with Computers project with an RGB camera-based module in a seamless manner with following objectives:
- Retrieve the pose skeleton keypoints of a human subject from RGB images.
- Transmit keypoints & RGB images of hands, head to clients for gesture recognition.
- Write a wrapper for OpenPose library that does pose skeleton detection.
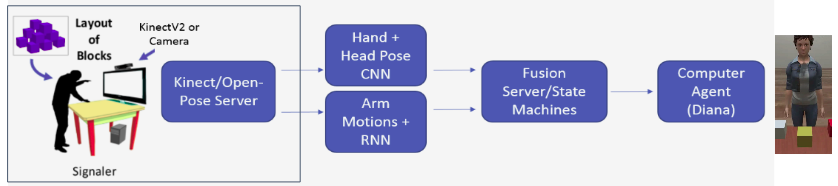
Here is the comparison between old and new front-end for our CwC pipeline.

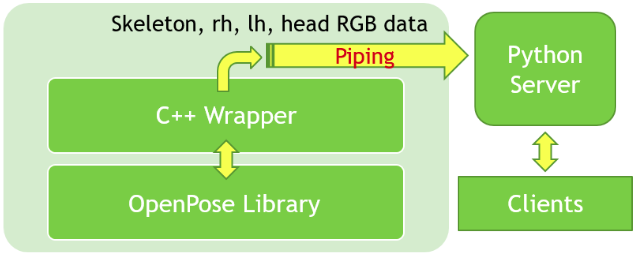
System Design: C++ wrapper and Python server:
- The C++ wrapper extracts pose skeletons from frames captured by a web-cam and uses these keypoints to crop the RGB images of hands and the head of the primary person in the video.
- The Python server is responsible for communicating with the wrapper process to collect the skeleton keypoints, hands and head images for primary (engaged) person in the frame.
- Server accepts four clients: skeleton, right hand, left hand, and head client.
- For every frame processed by OpenPose, the server sends corresponding data to four clients.
CwC demo with RGB-based front-end:
System Details
- Primary person is the closest person in the center of frame. With only 2D skeletons, it’s challenging.
- We calculate the average expanse (length) of the limbs of candidate persons present in a central window and choose the closest person based on a fixed threshold of limb length (51 in our case).
- Outputs 18 keypoints (x, y pixel locations of body parts + confidence) for people in the image frame.
- ~15 FPS on 320x240x3 input on NVidia GTX980.
- Server sends keypoints to arm motion recognition.
- Wrapper crops a 64x64x3 image for left hand, right hand, and head; Server sends them to hand and head clients for pose recognition.
Conclusions:
- We successfully implemented & tested the system by seamlessly switching from Kinect-based front end. Hands-on testing with the AI agent proved that it’s possible to get complex block structures build from the agent even with a RGB sensor.
- The system ran with no significant lag, but it needed specific conditions (e.g., bright light).
- We demoed the system at DARPA in Dec 2017.
- We hope that it can possibly replace the Kinect sensor, making our project demo more portable.
- In future, we aim to improve the performance in terms of fps and input image resolution.
References:
- Openpose Library: github.com/CMU-Perceptual-Computing-Lab/openpose
- Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields, Z Cao, T Simon, S Wei, Y Sheikh, arXiv:1611.08050, 2016