
Hadoop MapReduce: Word Count & Creating N-gram Profile for the English Literature (Gutenberg) Corpus
Introduction:
An N-gram is a contiguous sequence of N items from a given sequence of text or speech [1]. Probabilistic modeling of N-grams is useful for predicting the next item in a sequence in Markov models. For sequences of words, n-grams comprising of 1 word are called as unigram (1-gram). For set of 2 words, it's called as bigram (2-gram), for set of 3 words it's called as trigram (3-gram) and so on. For example, consider following sentence:
Let's study Big Data
The 1-grams for this sentence are ["Let's", "study", "Big", "Data"]. The 2-grams are ["__, Let's", "Let's, study", "study, Big", "Big, Data", "Data, __"]. Here, "__" represents the empty space before and after the sentence which helps to distinguish whether the word was used in the beginning or the end of the sentence or whether word was paired with other words.
N-gram analysis finds applications in many areas such as sequence prediction, sequence completion (such as the one in Gmail's August 2018 updated version), plagiarism detection, searching for similar documents, sentiment analysis automatic authorship detection, and linguistic cultural trend analysis. Not to mention that Google has already spent several thousands of hours doing research in this field given that it helps them in many products such as Google search engine, Gmail, Google Docs, Google Assistant, Google Voice transcription, and many more. They have created a great tool called Google Ngram Viewer which allows you to analyse words from English (as well as several more languages) for their frequency of use over time, occurrences in specific corpus, etc. You could get more information about this tool here on info their page.
For this project, the goal was to create an N-gram profile of a corpus of modern English literature formed by subsetting around 1GB of dataset that included more than 2500 books from Gutenberg project [2]. Major steps involved: (1) Extracting all the unigrams and bigrams, (2) Computing the frequency of each unigram and bigram, and (3) Ranking the unigrams and bigrams based on those frequencies. I used Hadoop's MapReduce framework to generate the ngram profiles.
Dataset:
Dataset - that was provided to us during the class - was compiled from the set of EBook files available as a part of Project Gutenberg. It was a small subset of size ~1gb consisting of lines from several books from the Project Gutenberg. Each line looked as follows:
AUTHOR<===>DATE<===>A SINGLE LINE FROM THE DATASET FILE
A specific example would be:
Arthur Conan Doyle<===>June 19, 2008<===>"Well, by his insufferable rudeness and impossible behavior."
For this project we were instructed to work with author's last name from AUTHOR field (last author in case of multiple authors) and only the year part of DATE field. We converted the words into lowercase to make them case insensitive. All the gender and tense identifier are treated as a separate word. Meaning "he" and "she" were treated separately. Words "have" and "has" were treated as two separate words.
Methodology:
The ngram profile analysis generates following:
- Profile 1-A: A list of unigrams sorted by unigrams in an alphabetical ascending order. Within the same unigram, the list should be sorted by year in an ascending order.
- Profile 1-B: A list of unigrams sorted by unigrams in an alphabetical ascending order. Within the same unigram, the list should be sorted by author’s last name in an ascending order.
- Profile 2-A: A list of bigrams sorted by bigrams in an alphabetical ascending order. Within the same bigram, the list should be sorted by year in an ascending order.
- Profile 2-B: A list of bigrams sorted by bigrams in an alphabetical ascending order. Within the same bigram, the list should be sorted by author's last name in an ascending order.
Outputs:
Here are some snippets from the outputs of map reduce program for four profiles mentioned above. If you are interested you could get the entire files from a cloud bucket as below:Profile-1A, Profile-1B, Profile-2A, and Profile-2B. And the source as well.
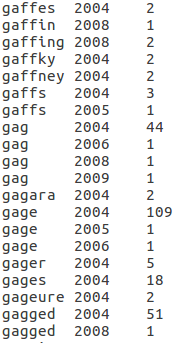
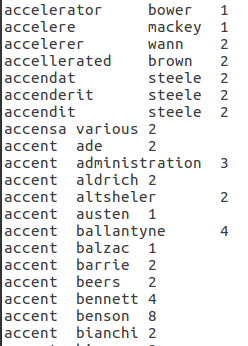
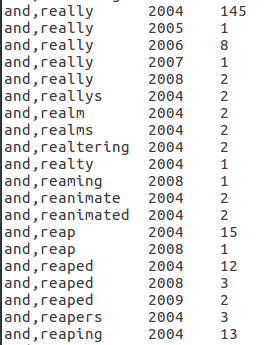
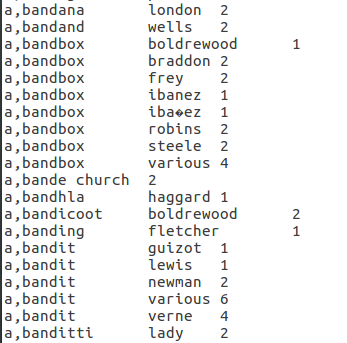
References:
- https://en.wikipedia.org/wiki/N-gram
- https://www.gutenberg.org
Note: Some of the content for this post is taken from course material of CS435 (CSU) written by Prof. Sangmi Lee Pallickara and GTAs.